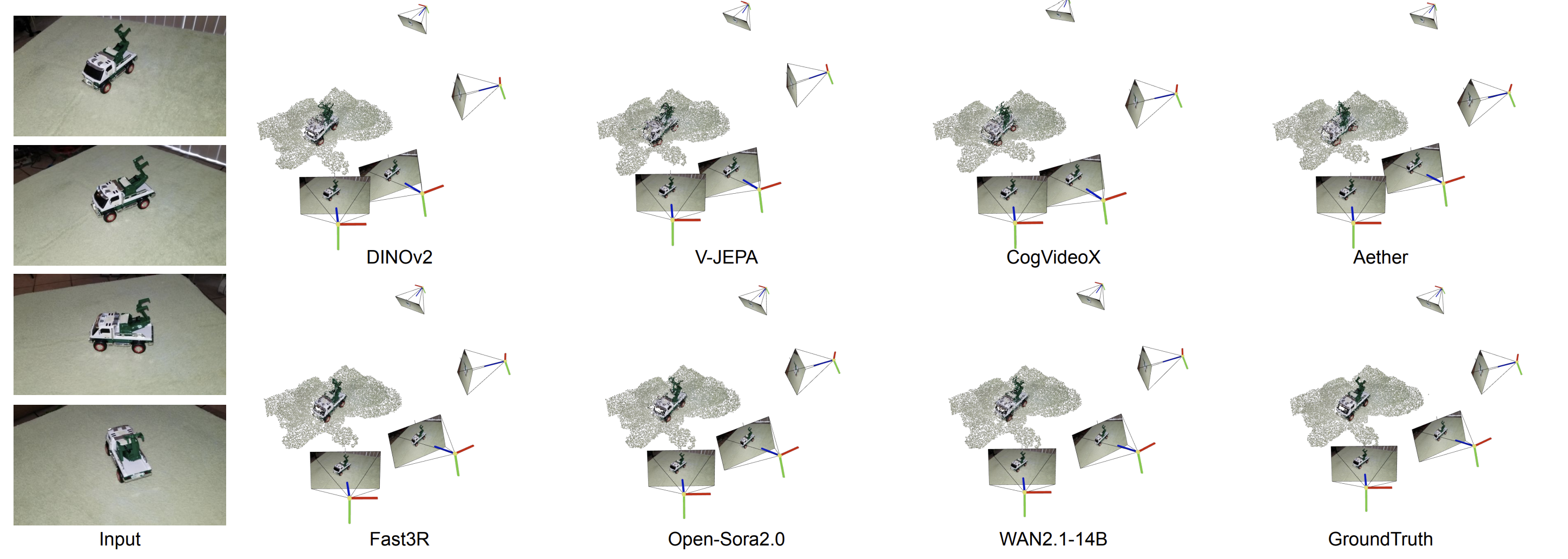



The per-frame image baseline (DINOv2) can fail catastrophically on difficult scenes, while top video generators often retain coherent geometry. Among them, WAN2.1-14B typically produces the sharpest and most accurate point clouds overall.
TL;DR: After training on large 2D videos, will video foundation models (VidFMs) naturally encode 3D structure and ego-motion? Our study reveals that state-of-the-art video generators develop strong, generalizable 3D understanding even compared to 3D experts, despite being trained only on 2D video data.
Videos are continuous 2D projections of 3D worlds. After training on large video data, will global 3D understanding naturally emerge? We study this by quantifying the 3D understanding of existing Video Foundation Models (VidFMs) pretrained on vast video data. We propose the first model-agnostic framework that measures the 3D awareness of various VidFMs by estimating multiple 3D properties from their features via shallow read-outs.
Our study presents meaningful findings regarding the 3D awareness of VidFMs on multiple axes. In particular, we show that state-of-the-art video generation models exhibit a strong understanding of 3D objects and scenes, despite not being trained on any 3D data. Such understanding can even surpass that of large expert models specifically trained for 3D tasks. Our findings, together with the 3D benchmarking of major VidFMs, provide valuable observations for building scalable 3D models.
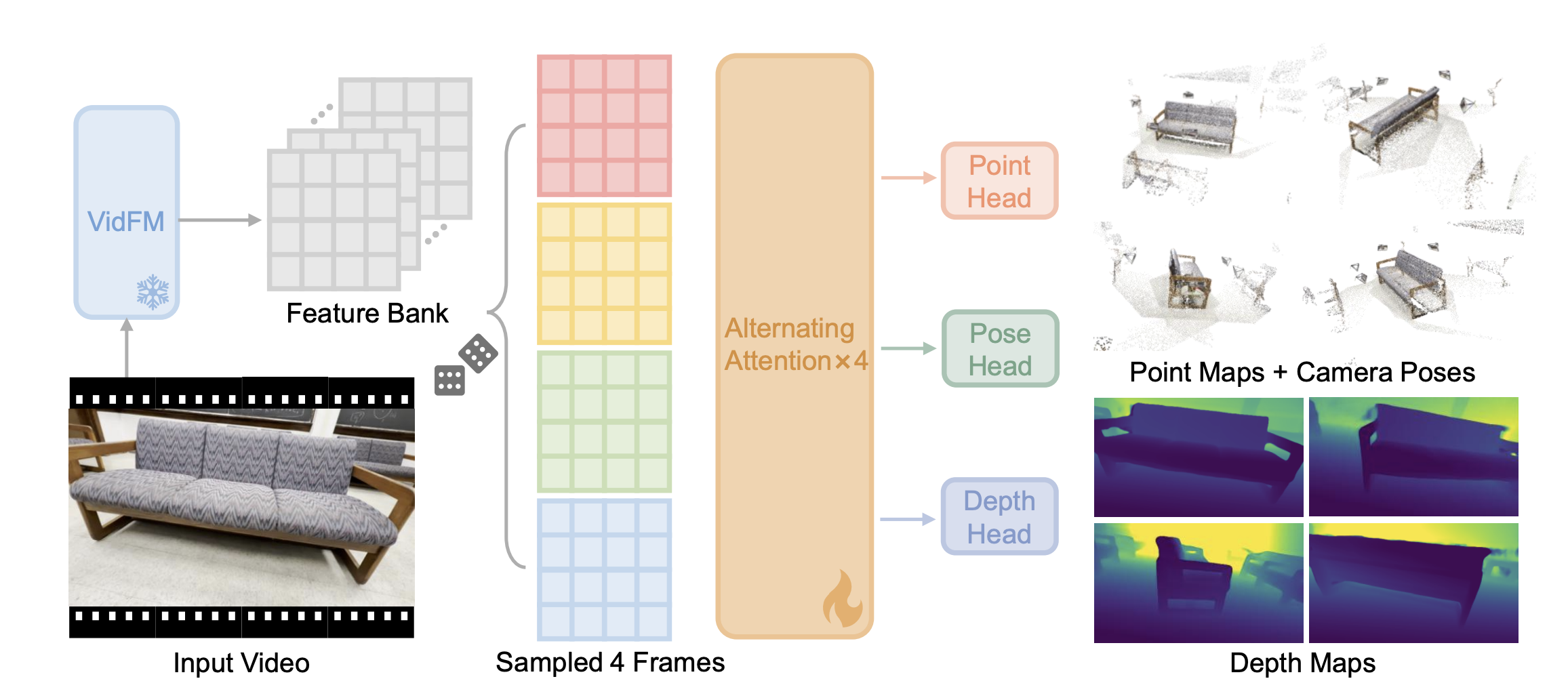
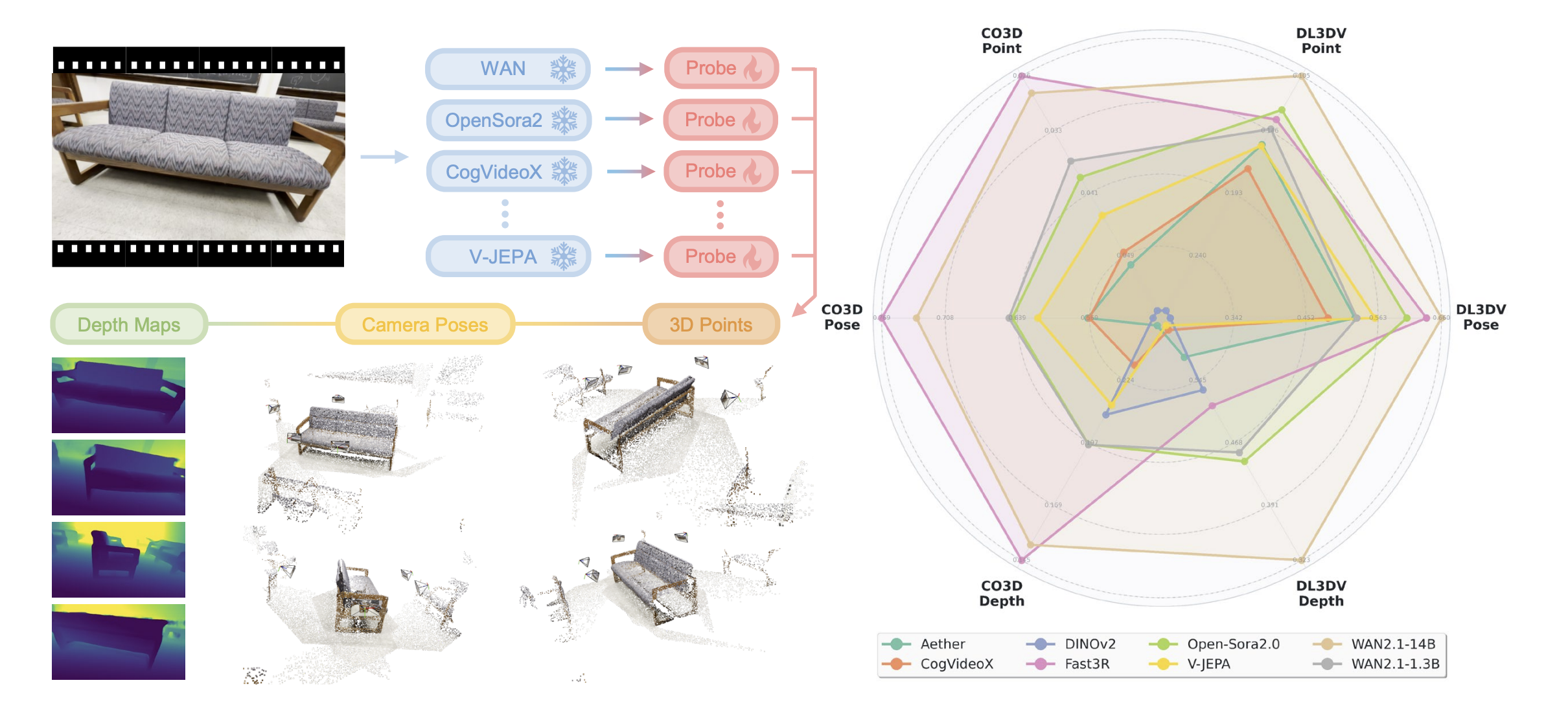
We design a model-agnostic probing framework that reads out 3D point maps, depth maps, and camera poses from frozen VidFM features using a shallow feedforward probe. The probing results quantify how much 3D is encoded in VidFMs' feature space, which we define as 3D awareness.
Specifically, we extract video features using various video foundation models and keep the features frozen. We sample four frames from the original video clip and fetch the corresponding feature maps from the video features. We train the probe by taking these spatial features as input, and task the probe to estimate point maps, depth maps and camera poses. We measure the estimation errors as the main indicators of 3D awareness.
Probe architecture: a shallow transformer with 4 alternating attentions + 3 readout heads (points, depth, pose).
Benchmarked models: video diffusion models (e.g., WAN2.1, Open-Sora2.0), self-supervised video models (V-JEPA), image models (DINOv2) and 3D experts (Fast3R).
Datasets: CO3Dv2 (objects) and DL3DV (large scenes).
Metrics: point-map error, depth error, and pose AUC at multiple thresholds.
We compare video diffusion models (CogVideoX, Aether, Open-Sora2.0, WAN2.1-14B), a self-supervised video encoder (V-JEPA), and two control baselines: DINOv2 (per-frame image features) and Fast3R (native 3D expert). Strong video generators (especially WAN2.1-14B and Open-Sora2.0) show high 3D awareness.
Interactive chart: Click legend items to show/hide models • Hover over lines for detailed metrics • Use toolbar buttons to select/deselect all or save as image
We visualize reconstructed 3D point clouds from frozen VidFM features with our shallow probe.
The per-frame image baseline (DINOv2) can fail catastrophically on difficult scenes, while top video generators often retain coherent geometry. Among them, WAN2.1-14B typically produces the sharpest and most accurate point clouds overall.
Explore the reconstructed 3D point clouds interactively. Select a scene and a method below to view the 3D reconstruction. Rotate, zoom, and pan to examine the geometry and camera poses from different viewpoints.
💡 Tip: Click and drag to rotate • Scroll to zoom • Right-click drag to pan
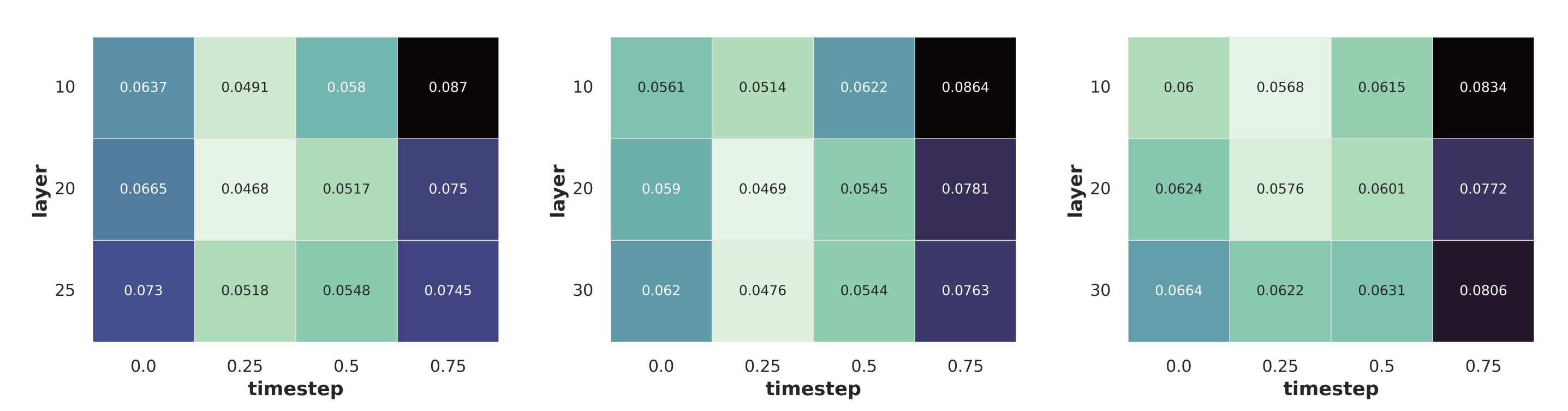
For video generators, we study which diffusion layer and timestep yield the most 3D-aware features by sweeping over three network layers and four denoising timesteps. Across all the models we study, the optimum is consistent: mid-network layers combined with an early-but-not-first time step, are significantly better than other layers and time steps.
VidFM features aren't just “diagnostically 3D-aware”, they are also practically useful, at least when 3D data and compute are limited. We replace the standard DINO-based feature backbone in VGGT with frozen WAN2.1-14B features, and train both models under a matched compute budget on CO3Dv2 and DL3DV. The VidFM-feature variant improves point/depth/pose metrics substantially, highlighting the advantage of video foundation model features for feedforward 3D reconstruction under limited 3D data.
| Method | CO3Dv2 | DL3DV | ||||||
|---|---|---|---|---|---|---|---|---|
| Point Err (↓) | Depth Err (↓) | AUC@5 (↑) | AUC@30 (↑) | Point Err (↓) | Depth Err (↓) | AUC@5 (↑) | AUC@30 (↑) | |
| Original VGGT (DINO) | 0.476 | 0.205 | 0.076 | 0.565 | 2.751 | 0.518 | 0.058 | 0.363 |
| VidFM-VGGT (WAN2.1-14B features) | 0.289 | 0.145 | 0.178 | 0.718 | 1.034 | 0.319 | 0.183 | 0.686 |
@article{huang2025vidfm3d,
title = {How Much 3D Do Video Foundation Models Encode?},
author = {Huang, Zixuan and Li, Xiang and Lv, Zhaoyang and Rehg, James M.},
booktitle = {arXiv preprint arXiv:2512.19949},
year = {2025}
}



